
by Neil Rangwani
Each year, as the NBA season kicks off, the “hot hand” debate (or, according to Wikipedia, the hot hand fallacy) resurfaces – are streaks of made shots indicative of a player getting hot, or are they just random occurrences? Here at Princeton Sports Analytics, we’re not happy discussing this with just anecdotal evidence (I mean, did you see Steph last night?), so we did some analysis(!). It turns out that (surprise) the data show that NBA superstars Steph Curry, LeBron James, and James Harden don’t get hot any more than a coin that lands on heads 5 times in a row does.
The argument that shot streaks are random is based on probability. Any time an event (with two outcomes) is repeated many times, streaks are bound to occur. To study whether NBA shot streaks are random, or if players have disproportionately long “hot” and “cold” streaks, I used shot-by-shot data from the 2014-2015 season (from nbasavant.com) and applied a geometric distribution framework.
The geometric distribution is a probability distribution that is used to model repeated trials of events that have two distinct outcomes, each of which occurs with a constant probability. NBA shots roughly fit these requirements – there are clearly two outcomes (makes and misses), and I’ll assume that a player’s season-long field goal percentage is the “true” probability that they make any given shot.
Using the geometric distribution, we can model the number of made shots in a row. Essentially, a streak means that a player makes a certain number of shots in a row and then misses the next. Mathematically, this is the probability of making k shots in a row (pk) multiplied by the probability of missing (1-p)k.
P(X = k) = pk * (1 - p)
Next, I applied this framework to the shot-by-shot data from last season for Steph Curry, LeBron James, and James Harden. Using the data and the geometric distribution, here’s the expected and observed shot streaks.
| Curry | James | Harden | |||||||
| Streak Length | Probability | Expected | Observed | Probability | Expected | Observed | Probability | Expected | Observed |
| 1 | 24.98% | 178.09 | 184 | 24.99% | 174.15 | 176 | 24.64% | 205.03 | 207 |
| 2 | 12.16% | 86.69 | 85 | 12.19% | 84.95 | 96 | 10.84% | 90.17 | 88 |
| 3 | 5.92% | 42.20 | 47 | 5.95% | 41.44 | 38 | 4.77% | 39.66 | 41 |
| 4 | 2.88% | 20.54 | 17 | 2.90% | 20.21 | 19 | 2.10% | 17.44 | 18 |
| 5 | 1.40% | 10.00 | 7 | 1.41% | 9.86 | 7 | 0.92% | 7.67 | 7 |
| 6 | 0.68% | 4.87 | 4 | 0.69% | 4.81 | 2 | 0.41% | 3.37 | 5 |
| 7 | 0.33% | 2.37 | 2 | 0.34% | 2.35 | 1 | 0.18% | 1.48 | 0 |
| 8 | 0.16% | 1.15 | 1 | 0.16% | 1.14 | 1 | 0.08% | 0.65 | 0 |
| 9+ | 0.15% | 1.09 | 0 | 0.16% | 1.09 | 0 | 0.06% | 0.51 | 0 |
Here’s a visual version of the same data:
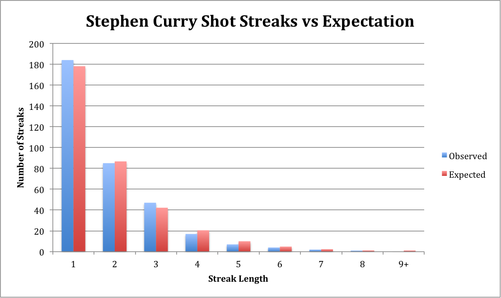
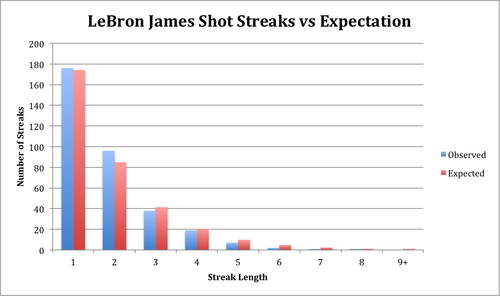
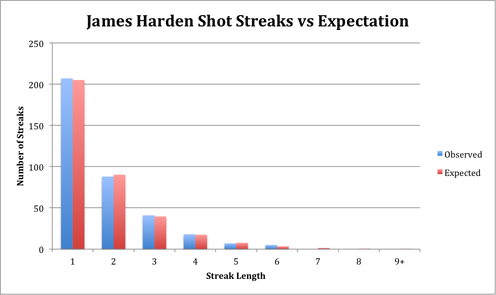
While it seems that the observed and expected distributions are close, we can actually quantify whether they are. We’ll use a chi-squared goodness-of-fit test to tell us whether the observed data fits the geometric distribution.
| p-value | Chi-Squared Test | Conclusion | |
| Curry | 0.89 | Fails | Random |
| James | 0.63 | Fails | Random |
| Harden | 0.89 | Fails | Random |
The p-value of a chi-squared test tells us the probability that the observed values are from the theoretical distribution. These p-values strongly suggest that the observed shot streaks are well explained by the geometric distribution.
Bringing this back to basketball… what we get from this analysis is that shot streaks match what we’d expect if they were truly random. Even NBA superstars don’t “get hot” – instead, since they tend to have higher field goal percentages in general, they naturally have longer streaks of made shots.
One thing to keep in mind, however, is that the model doesn’t account for timing. It’s totally possible that a player’s shot streaks are geometrically distributed overall, but when you isolate playoffs or overtime games, as examples, they tend to have longer streaks than expected. I mean, did you see LeBron in that Pistons game?

Is the data used in this study freely available?
Thanks,
Alexander
I’m interested in what answer you might get if you focused on the conditional probability that a player makes their next shot, given they made their last shot (or last N shots).
Most people don’t consider missing one shot to mean a hot streak has been broken. So the math above doesn’t debunk the popular belief.
@Alexander: The data is from nbasavant.com and is available for download.
@Zharrief: I agree with what you’re saying, but the purpose of the article was simply to model shots as a geometric random variable. There are certainly many other ways to study heat - performance vs expected performance given shot difficulty (maybe “hot” players take more difficult shots and overperform on those), impact of shot streak on shot selection, ability of a “hot” player to positively influence team performance (if a player performs well, maybe his teammates have more open shots), or probability of making the next shot given the current streak as you suggest. These are all ideas for future study (and some already have papers written on them)!
Also, your Chi-squared test fails. The test does not have a statistically significant p-value. This means the data does not fit the Geometrical distribution well. Since the Geometrical distribution has the assumption that shots are independent, and your data does not fit this distribution to a statistically significant degree, this math would indicate that the probability of making a shot is NOT independent of whether you just make a shot or not.
So you have basically disproven your own hypothesis.
LOL
“The p-value of a chi-squared test tells us the probability that the observed values are from the theoretical distribution. ” Not quite…It tells us the probability of finding the amount of deviance in the distribution assuming (!) that it came from the theoretical distribution. So, in this case, you’re obviously correct that the Chi Square indicates that the distribution is somewhat ok-fitting. But it’s certainly not the case that the chi-squared tells you the probability that you are correct.